OurBigBook Web implements what we call "dynamic article tree".
What this means is that, unlike the static website generated by OurBigBook CLI where you know exactly which headers will show as children of a given header, we just dynamically fetch a certain number of descendant pages at a time.
As an example of dynamic artic tree, note how the article "Special relativity" can be seen in all of the following pages:The only efficient way to do this is to pick which articles will be rendered as soon as the user makes the request, rather than having fully pre-rendered pages, thus the name "dynamic".
- ourbigbook.com/barack-obama/special-relativity as the toplevel article
- ourbigbook.com/barack-obama/physics as a child
- ourbigbook.com/barack-obama/natural-science as the child of a child

Dynamic article tree with infinitely deep table of contents
. Live URL: ourbigbook.com/cirosantilli/chordate
Descendant pages can also show up as toplevel e.g.: ourbigbook.com/cirosantilli/chordate-subclade
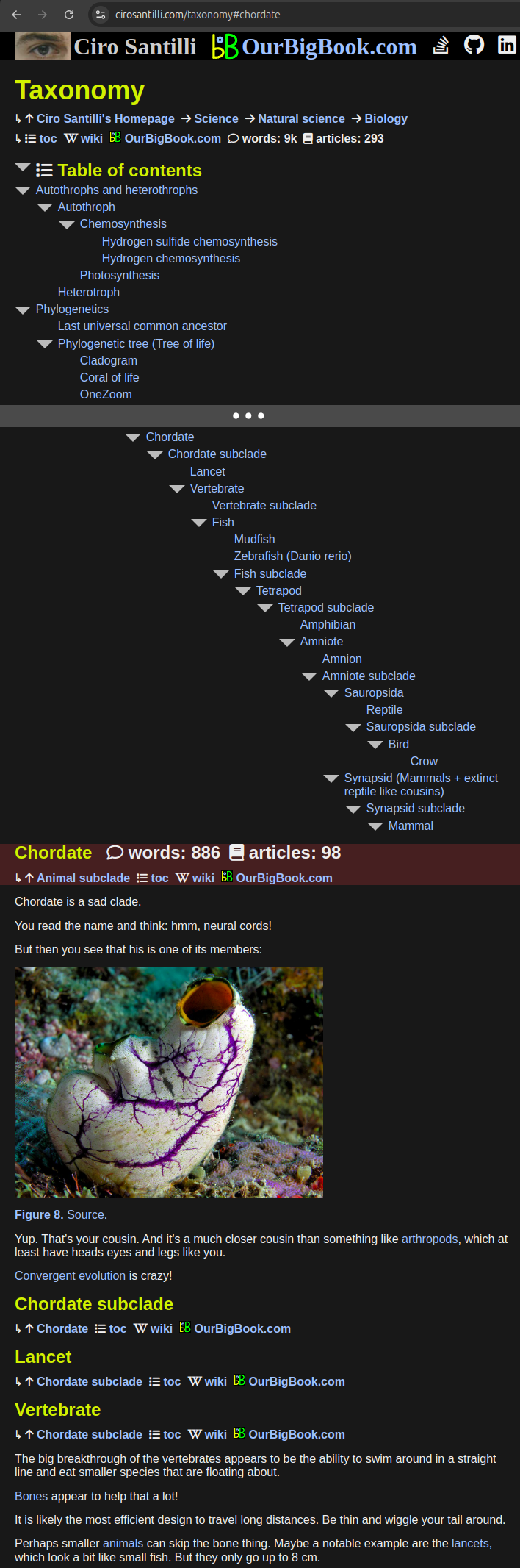
And this is how the same article looks on the static website
. Live URL: cirosantilli.com/taxonomy#chordateThe design goals of the dynamic article tree are to produce articles such that:
- each article can appear as the toplevel article of a page to get better SEO opportunities
- and that page that contains the article can also contain as many descedants as we want to load, not jus the article itself, so as to not force readers to click a bunch of links to read more
For example, with a static website, a user could have a page structure such as:
natural-science.bigb
= Natural science
== Physics
\Include[special relativity]special-relativity.bigb
= Special relativity
== Lorentz transformationIn the static output, we would have two output files with multiple pages:plus one split output file for each header if
natural-science.htmlspecial-relativity.html
-S, --split-headers were enabled:natural-science-split.htmlphysics.htmlspecial-relativity-split.htmllorentz-transformation.html
In this setup the header "Physics" for example is present in one of two possible pages:
natural-science.html: as a subheader, but Special Relativity is not shown even though it is a childphysics.html: as the top header, and Special Relativity is still not shown as we are in split mode
In the case of the dynamic article tree however, we achieve our design goals:We then just cut off at 100 articles to not overload the server and browsers on very large pages. Sometimes those pages can still be accessed through the ToC, which has a larger limit of 1000 entries. We also want to implement: load more articles to allow users to click to load more articles.
- "Physics" is the toplevel header, and therefore can get much better SEO
- "Special Relativity", "Lorentz transformation" and any other descendants will still show up below it, so it is much more readable than a page
And all of that is achieved:
- without requiring authors to manually determine which headers are toplevel or not to customize page splits with reasonable load sizes.
- without keeping multiple copies of the render output of each page and corresponding pre-rendered ToCs. On the static website, we already had two rendering for each page: one split and one non-split, and the ToCs were huge and copied everywhere. Perhaps the ToC side could be resolve with some runtime fetching of static JSON, but then that is bad for SEO.
The downside of the feature is slightly slower page loads and a bit more server workload. We have kept it quite efficient server-side by implementing the page fetching with a nested sets implementation.
We believe that dynamic article treee offers a very good tradeoff between server load, load speeds, SEO, readability and author friendliness.