This is a list of project announcements such as new features sorted in chronological order, from the newest to oldest.
Significant entries will have a corresponding announcement on the following official accounts:
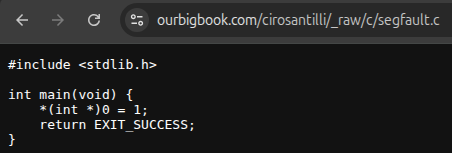
It is now possible to have create file uploads on OurBigBook Web, e.g.:You can upload images, source code, or any other type of file.
Previously, you'd just get broken links when publishing to OurBigBook Web if you linked to your files with the
\a macro or other related constructs.The implementation attempts to follow what already existed for static websites as closely as possible.
The current implementation has a few limitations which should be fixed one day:
- there is no web UI for file upload, it is exposed via CLI only
- file previews don't show under corresponding
_filearticles as they do on static _filearticles are not properly auto-generated for files that don's have explicit articles, we just show_rawunder_file
Announced at:
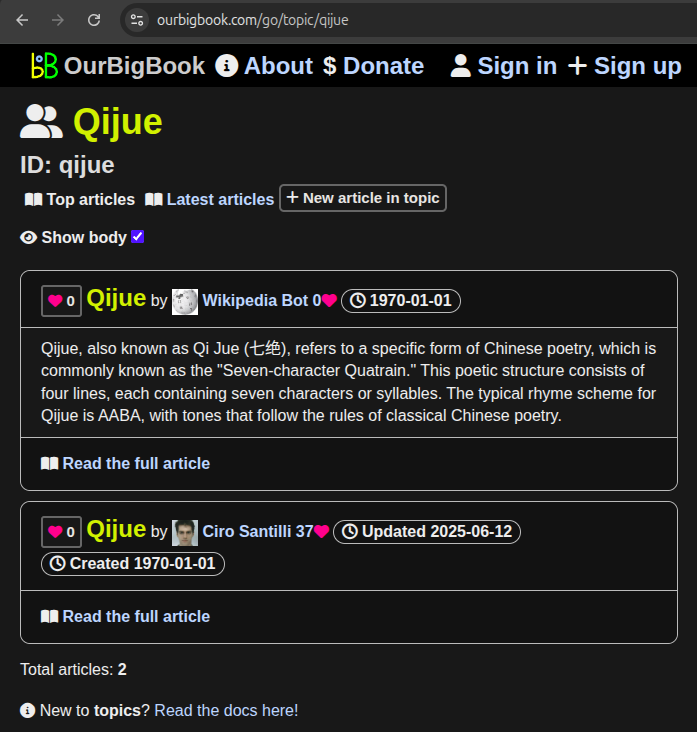
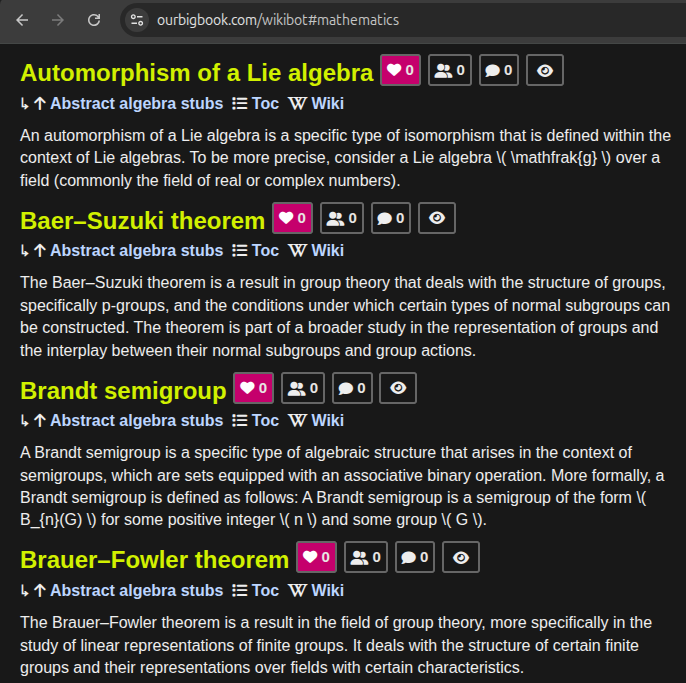
We've used gpt-4o-mini to automatically populate the 100k+ wikibot articles. The process is described at: Section "Wikibot LLM body population". The entire generation was completed for only $3.
Some of the abstracts can be seen e.g. under Wikibot's user page: ourbigbook.com/wikibot#mathematics or under specific topics such as: ourbigbook.com/go/topic/qijue
We've limited the output to 100 tokens each, and for each topic X simply queried"
What is X?Unfortunately there is quite a bit of "obviously LLM generated trash" in those. Some of it we sedded out, but some stray markdown and lists with a single item cut short due to the 100 token limit remain.
This was mostly for fun, but it might sometimes serve as a good quick definition on previously empty topic pages and articles on the same topic under a given article.
Hopefully it will also kick some of our pages out of Google's "Soft 404" limbo; pages that it refuses to index because they seem empty and it considers them as being essentially 404s, inexistent pages, and bring in some tail end traffic for the more niche subjects.
Automatic topic linking is also active on these as everywhere else on the site, which ends up interlinking everything automatically.
Announced at:
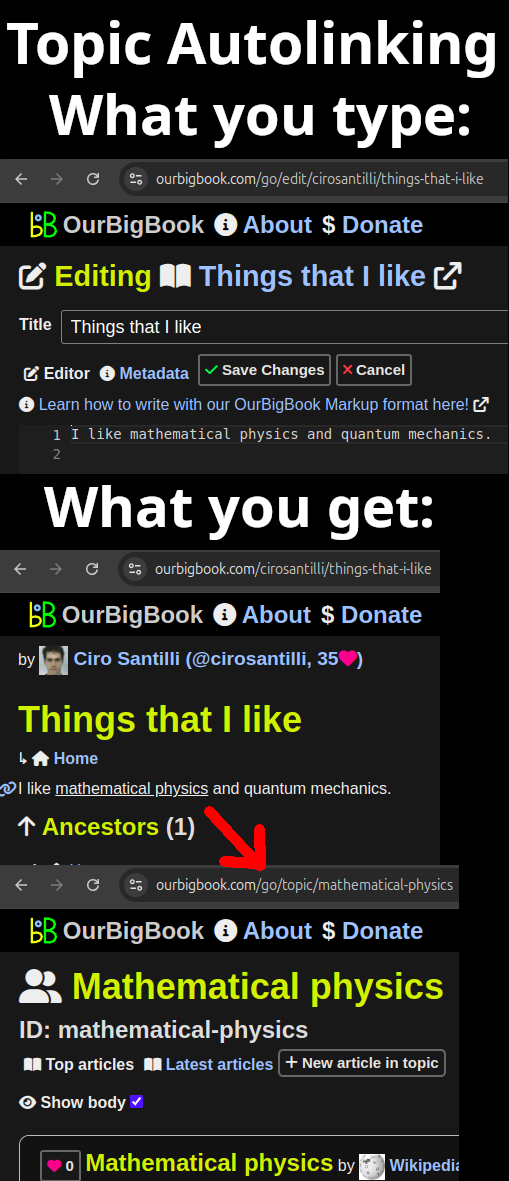
With Automatic topic linking, regular text gets automatically converted to links to topics if part of the text matches an existing topic.
Announcements:
Tagged
As described at: github.com/ourbigbook/ourbigbook/issues/346, starting December 2024 and increasingly so through January and February 2025, OurBigBook.com has been increasingly targeted by a SAPMmer group.
About half of the SPAM posts were advertising cryptocurrency recovery services, but other scammy products were also advertized.
They usually create a few posts every day, but they are very persistent and keep coming back day after day.
The spammers were rather sophisticated:
- almost always one SPAM post per account
- all accounts use gmail addresses, presumably bought in bulk
- the SPAMers use one of a variety of free VPN, most notably ExpressVPN, NordVPN and PIA
At first we were rather amused that there would be human labor so cheap as to make such a work economically feasible.
Adding SPAM to a website that has zero users and almost no views. Amazing!
And it has to be manual work because the website is already protected by OurBigBook Web reCAPTCHA setup.
Furthermore all of the above strongly indicate a well organized SPAM operation that spams across a variety of websites for a variety of clients.
But what really impressed us the most was ourbigbook.com/alannakennedy/top-ways-to-recover-funds-from-cryptocurrency-scam-iforce-hacker-recovery They actually upvoted a single post from 13 other accounts, making it by far the top article on OurBigBook.com as visible at: ourbigbook.com/go/articles?sort=score

Screenshot showing voting manipulated SPAM as the most highly upvoted article on OurBigBook.com
. Source. Initially Ciro was debating to himself if he should allow this to continue or not. It is kind of fun to see them work and build a database of compromised gmail addresses.
But finally, Ciro decided to put a stop to it mostly because:
- they create so many accounts that it would take a lot of effort to go over all of them to decide which accounts are legit or not if in the future we wanted to nuke the SPAM accounts
- manipulating the voting system was a step to far
As a result, we have implemented the following features on the website, which should completely kill off this wave of SPAM, while hopefully having little impact to legitimate users:
- OurBigBook VPN blocking: we now detect and forbid users from signing up from IPs of well known VPNs. The detection is done via API calls to ipapi.is/ which allows fo 1000 free daily requests. We only make the requests after reCAPTCHA, and if that service is ever down for some reason, we just skip the check instead
- OurBigBook Web signup IP blacklist: additionally, a small percentage of the SPAM was coming from Pakistani IPs which were not marked as part of a VPN. So we have also given the ability for admins to block some IPs manually to cover those
- Account locking: for SPAM that goes through, we intend to use this new feature to lock the SPAM accounts, which prevents them from further editing the database in any way, e.g. creating articles
Furthermore, we will also use the pre-existing unlisted article feature to unlist any particularly noisy spam such as the vote manipulated post.
Announcements:
When searching articles and topics on OurBigBook Web PostgreSQL, which is the case for OurBigBook.com:Previously, searches would only work if they were exactly a prefix of the title ID.
- each searched word can match exactly within any word of article IDs
- the last word is considered as a prefix, and matches the start of any word of the ID
For example, if you search:then it will match titles such as:since it contains both:
calculus funFundamental theorem of calculus- the full word
calculus fundamentalwhich contains the prefixfun
This feature implemented efficiently by using PostgreSQL's built-in full text search module.
OurBigBook Web search highlighting full text search
. Source. Announcements:
It is now possible to send a link to one of your articles to all of your followers on OurBigBook Web with the Article announcement feature. You can also add a short custom message to the announcement.
Article announcement button on OurBigBook Web
. Source. 
Modal that opens up after clicking the article announcement button on OurBigBook Web
. Source. Announced at:
Tagged
We have now cleaned up the tab navigation on OurBigBook Web pages such as:to have two levels organized by:
- index page: ourbigbook.com/
- user articles page: ourbigbook.com/go/user/cirosantilli/articles
- "object type" on the top row, e.g. articles, users, etc.
- "further specifiers" on the bottom row, e.g. sorting and filtering
Two-level tab navigation on OurBigBook Web
. Source. Announced at:
Starting now, if you have a scoped header such as then if you visit either the instead of just:as before.
Sample code in:= x86 Paging
{scope}
== Sample codethe title now shows something like:
x86 Paging / Sample codeSample codeThis makes it easier to identify what scoped pages are about.
When a page under a scope is at toplevel, the scope prefix is clearly shown
. Source. Announcements:
This give a chance for users to see what else is present in that topic to better decide if it is a good fit for the article.
Also, the topic ID now shows more clearly on each topic page to help users understand that each topic has its own ID that determines which articles will show up in the topic.
Topic link showing while creating a new article on the web editor
. Topic ID showing on the topic page
. Announcements:
Previously, to create a new article that is a child or sibling of another article, you'd need to navigate to the article itself.
Now you can also do it from the table of contents. This is an intuitive place to do it from, since you can browse the article tree and decide the best location to insert a new article from there.
You can add a new article under or after another on OurBigBook Web from the table of contents
. 
After clicking the plus sign, a popup appears that allows you to add the new article
. Announcements:
You can now update your profile picture on OurBigBook Web by uploading an image to the website like in a normal website.
Previously, we only supported linking to an external image URL. Now this is not allowed anymore and you must instead upload your image to the website. Existing external links will continue to work, but if you want to update the profile picture again, then you will need to upload your own next time.
Besides being a basic feature expected from any modern website, this is the first instance of "static file upload" on the site, and serves as part of a more general static file upload mechanism that can be later reused for other important features like uploading images for your articles.
This initial implementation is very simplistic: we are just storing the image directly in the database. We will look into migrating to a more proper static file solution later on if this starts to hurt performance. We're using the sharp Node.js image processing library, a frontend to libvips, to downsize input images as needed.
OurBigBook Web profile picture upload
. Clicking on the current profile picture opens up a file dialog which allows you to select an image from your computer to be your new profile picture.Announcements:
The
\H disambiguate argument now shows on most navigation locations including:This makes it easier to understand what the topic is about when disambiguate is fundamental.
OurBigBook Web tagged article list with disambiguate
. This change adds the "(mathematics)" disambiguate to "Classification (mathematics)", which makes the header much clearer than just "Classification".
Announcements:
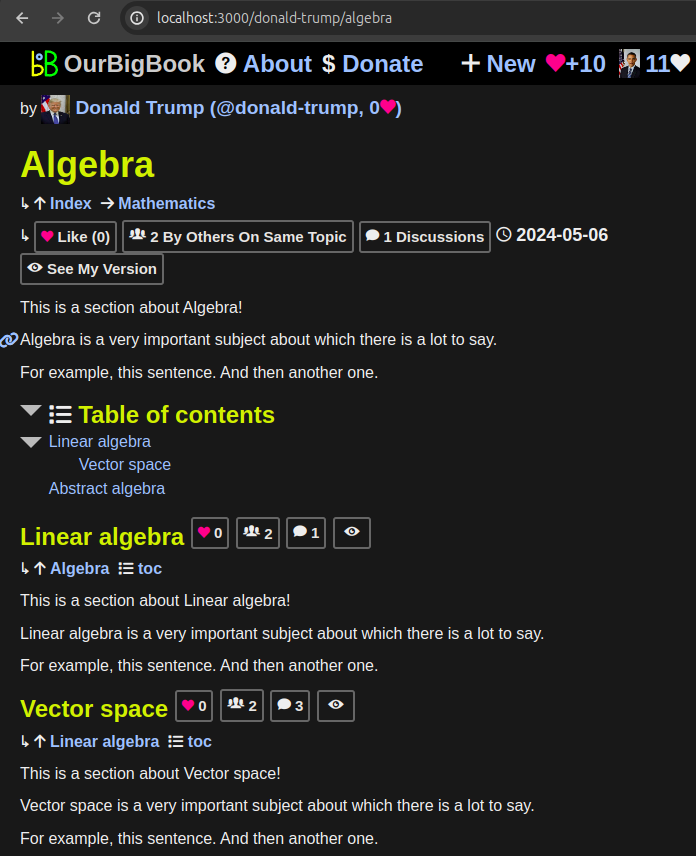
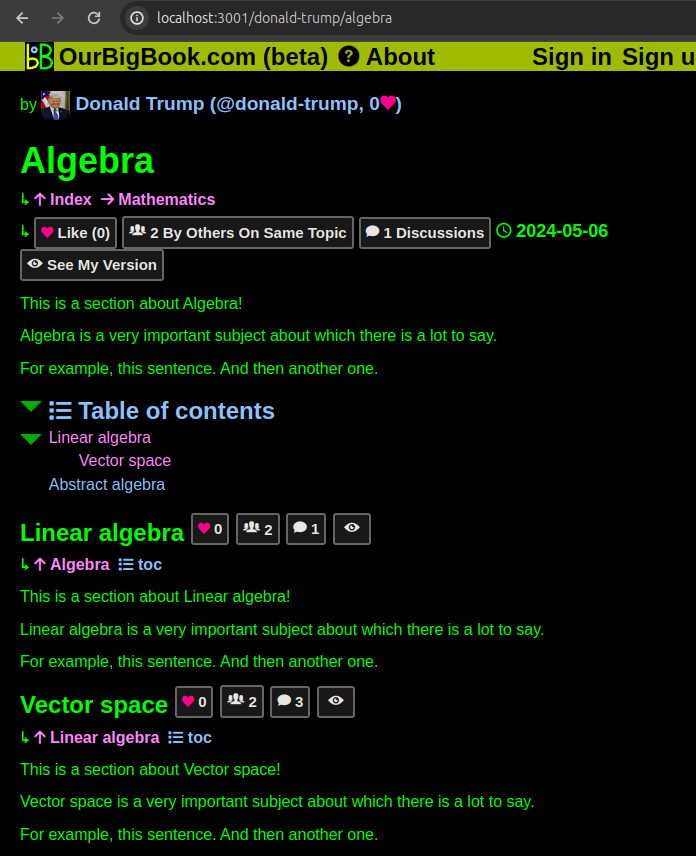
For some time we have been listing certain "cross article" metadata at the bottom of articles on both
-W, --web and static.For example, on both:you can see a list of articles tagged by the given articles at the end of the page.
Now, only on
-W, --web, you can also see these article lists with the article content itself, for example: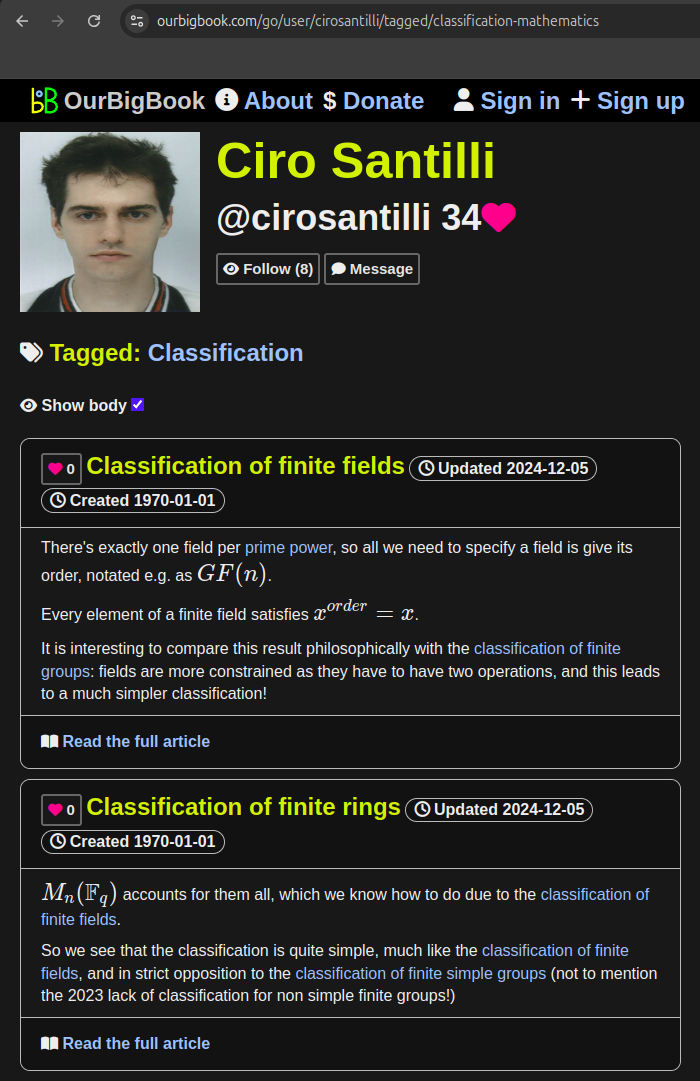
Figure 19. OurBigBook Web tagged article list with body demo. Live URL: ourbigbook.com/go/user/cirosantilli/tagged/classification-mathematicsAccessible via header links to the Tagged sections both on toplevel and non-toplevel: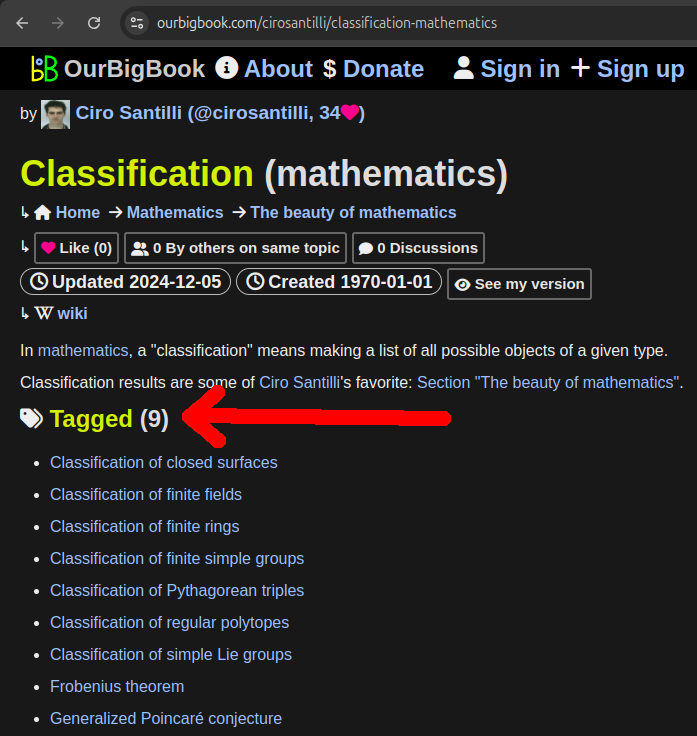
Figure 20. OurBigBook Web toplevel header link to tagged article list. Live URL: ourbigbook.com/cirosantilli/classification-mathematics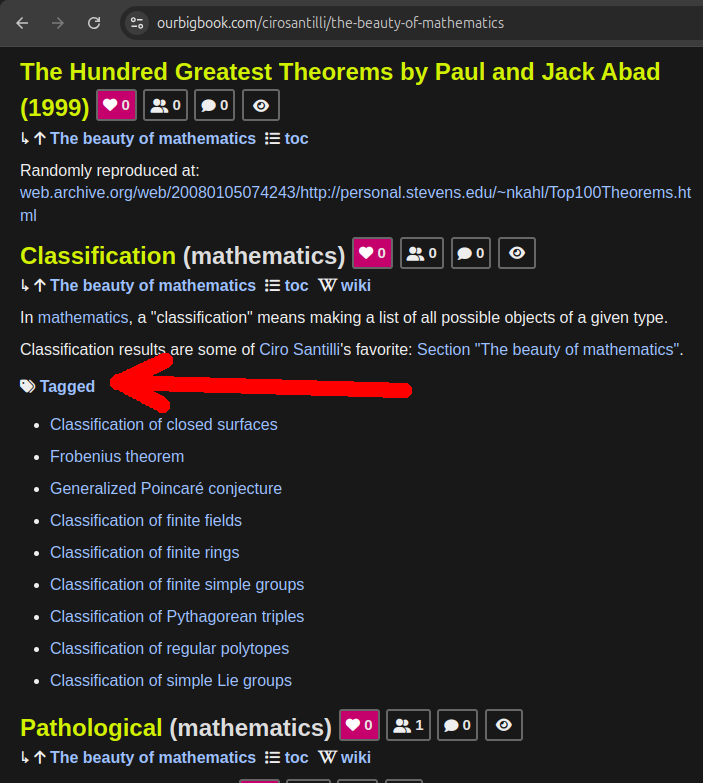
Figure 21. OurBigBook Web non-toplevel header link to tagged article list. Live URL: ourbigbook.com/cirosantilli/the-beauty-of-mathematics#classification-mathematics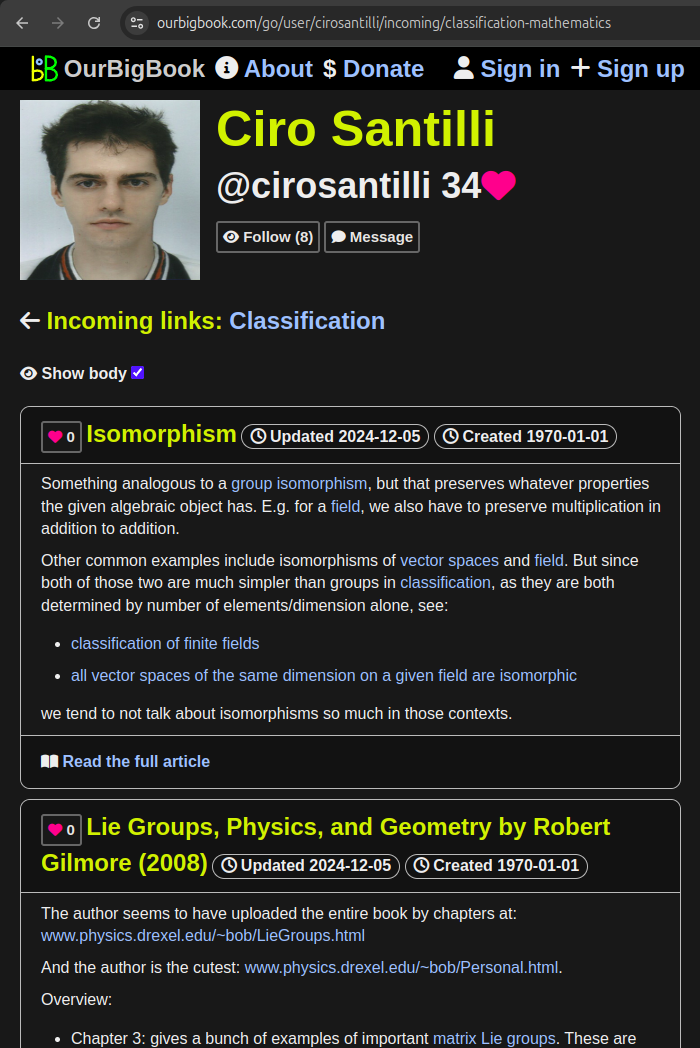
Figure 22. OurBigBook Web incoming article list with body demo. Live URL: ourbigbook.com/go/user/cirosantilli/incoming/classification-mathematics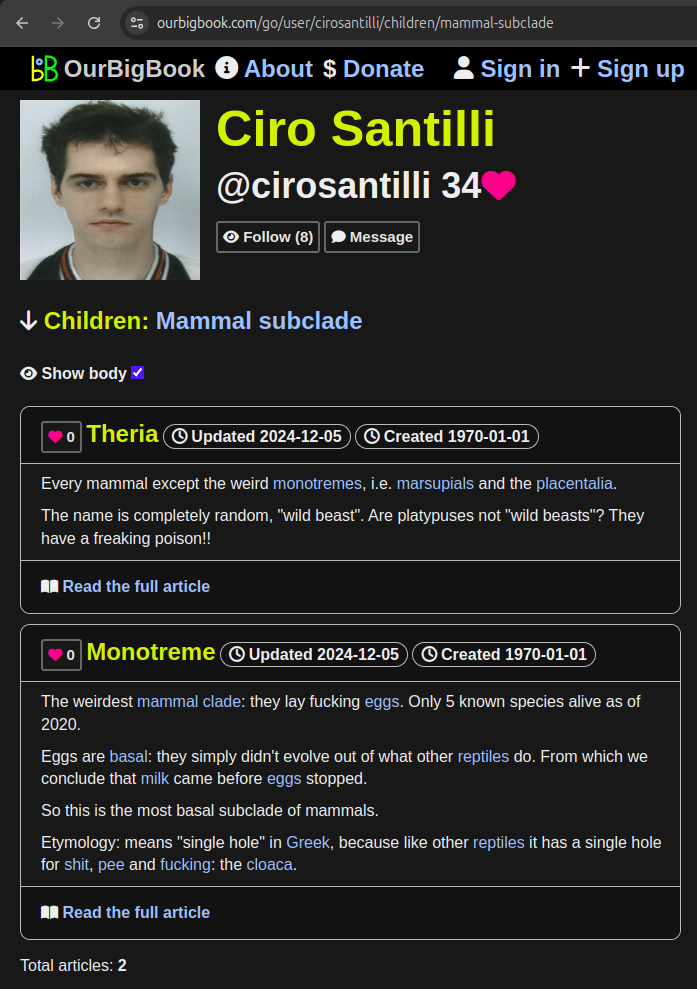
Figure 23. OurBigBook Web incoming child list with body demo. Live URL: ourbigbook.com/go/user/cirosantilli/children/mammal-subcladeAccessible via the newly added "was limited to" info boxes when there are too many articles under a tree to show on the page: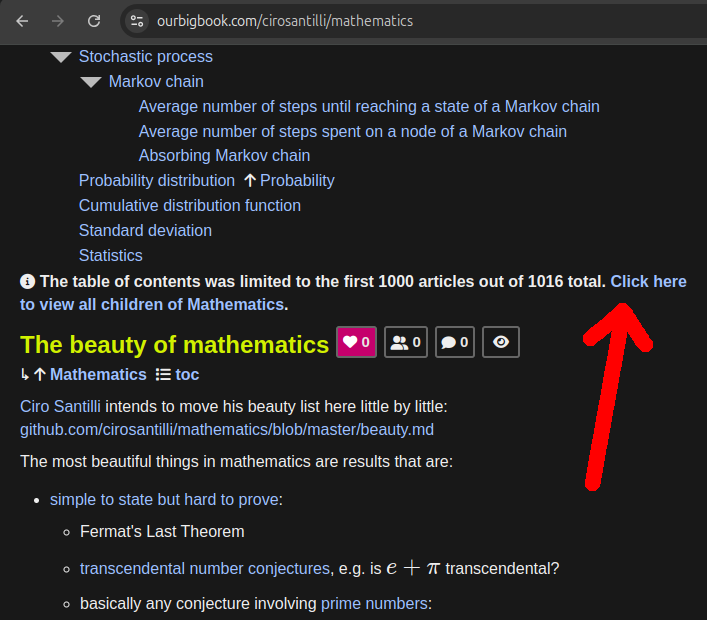
Figure 24. OurBigBook Web limited ToC size link to full child article list. Live URL: ourbigbook.com/cirosantilli/mathematics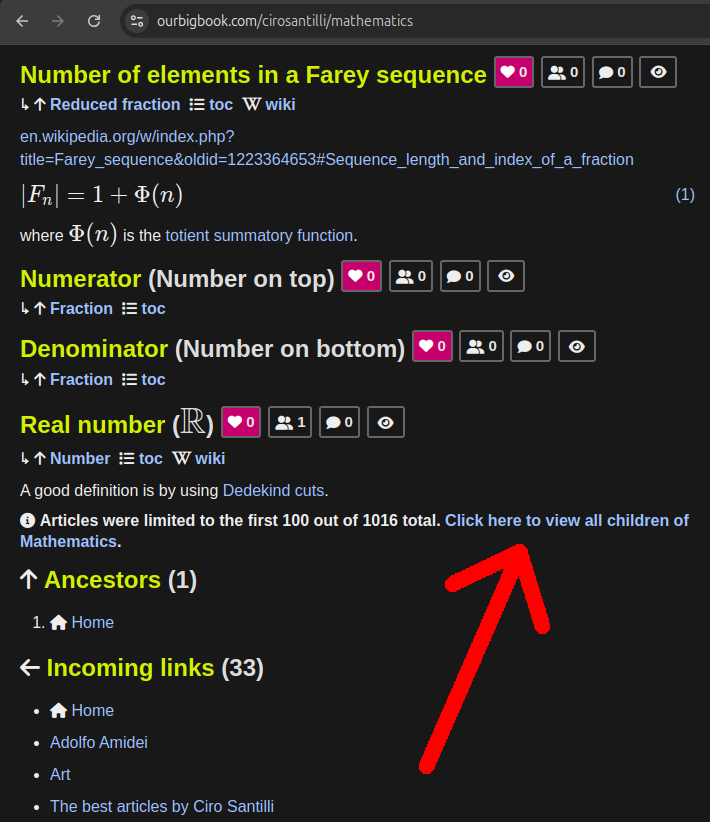
Figure 25. OurBigBook Web limited descendant articles link to full child article list. Live URL: ourbigbook.com/cirosantilli/mathematics
The initial motivation for this was to be able to quickly browse through tagged articles, especially since the recent tagged headers show under non-toplevel headers.
Another motivation for this is the ability to be able to view such lists with pagination when a large number of items exists. While we don't currently limit tagged and incoming links listings, children listings are already useful as we currently limit dynamic article tree ToCs to 1000 entries, so that children listings open up a way to explore such large article trees.
This is the type of cute thing that can only be done efficiently on
-W, --web, where we can use an actual database to build up a precise response as requested. On static websites, this would either require lots of repetition on pre-rendered HTML, or making several JavaScript requests to fetch individual articles from the server, which could risk overloading the server.Announcements:
It is now possible to search through ToCs on static websites renders. Only items under the current ToC are searched for.
Ideally we should also implement a mechanism to search across all headers from any page. This would require generating a JSON with all the headers and their renders and fetching it from JavaScript. Doable but more work. For now we keep it simple and only search the existing ToCs.
OurBigBook static search demo: empty search
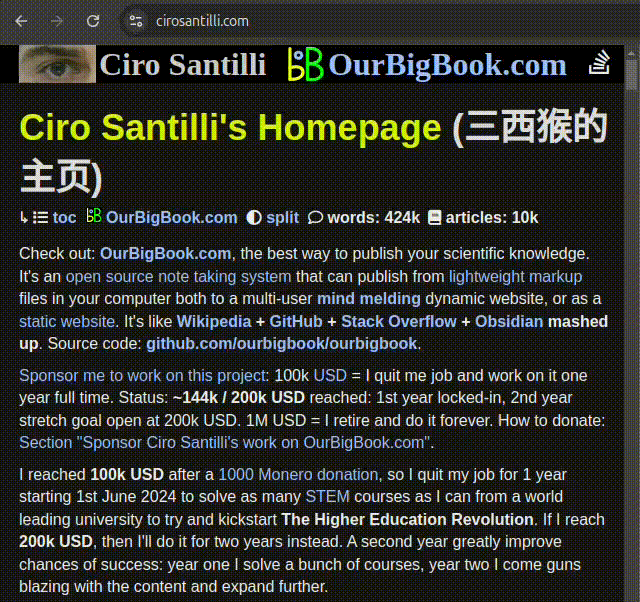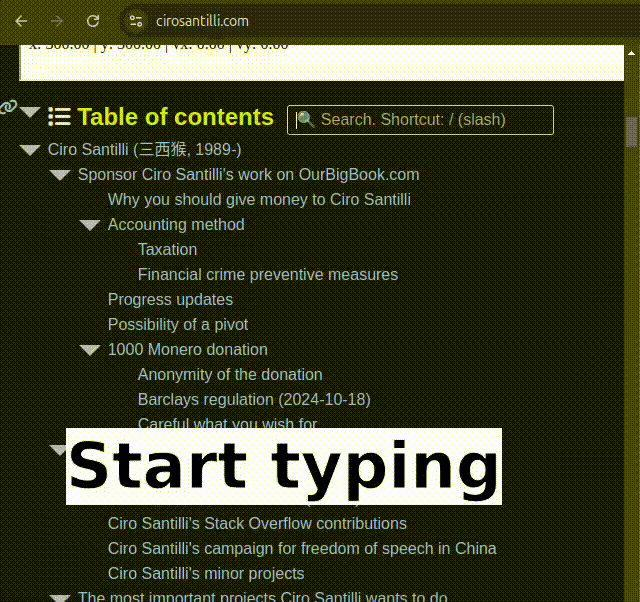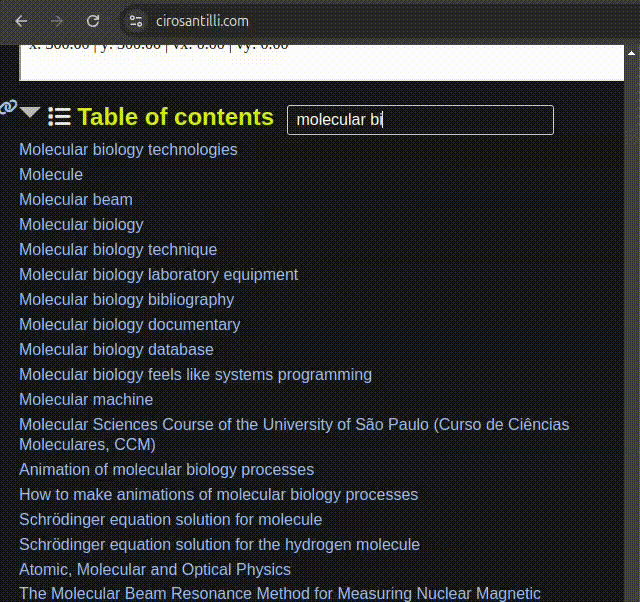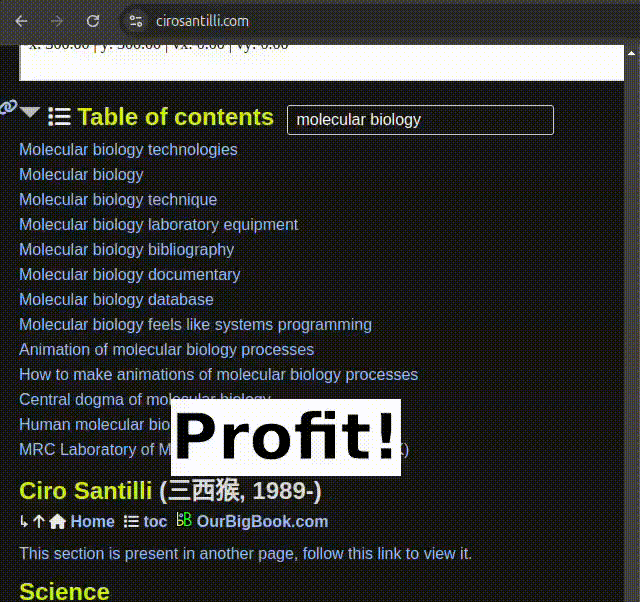
. OurBigBook static search demo: search for "molecular biology"
. 
OurBigBook static search demo video
. Announcements:
It is now possible to search articles and topics by a given ID prefix.
We are going to look full text search for non prefix searches next. But at least the frontend is working and any improvements will be backend only.
Simultaneous search and sort (e.g. sorting by date and score) is also not available at present, once you start searching it disables sorting. We will also look into how to implement that.
Related issue: github.com/ourbigbook/ourbigbook/issues/263
Announcements:
Previously, tagged articles would only show up at the bottom of the page for the toplevel header, e.g. you'd only be able to see which articles are tagged as:under the split header page:but not under the non-split:Now tagged articles are also shown under non-toplevel headers, both on static websites and OurBigBook Web.
Documentary filmcirosantilli.com/documentary-filmcirosantilli.com/film#documentary-filmThis makes it much easier for readers to view the tags, as it does not require them to click the header to view it as the toplevel and then go to the bottom of the page.
It also means that headers that are used primarily as tags and which would be otherwise empty now show some meaningful content.
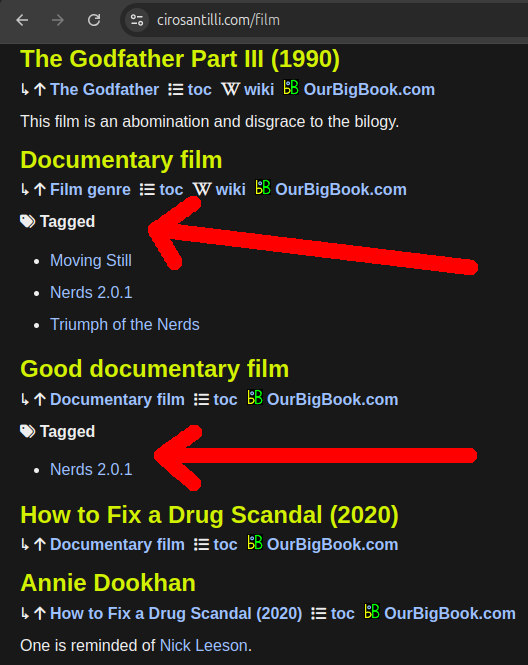
Non-toplevel tagged headers demo
. Visible live at: cirosantilli.com/film#documentary-filmAnnouncements:
OurBigBook CLI now forces you to write a consistent tree of headers by default, including e.g.:
- can't have text under the current header after Includes. E.g. this is not allowed anymore:You need instead something like:
= Vertebrate Vertebrates are cool. \Include[mammal] And they have vertebrae.= Vertebrate Vertebrates are cool. And they have vertebrae. \Include[mammal] - files must start with a h1 header and contain only a single h1 header. E.g. in
vertebrate.bigbthis is not allowed because it does not start with a header:Neither is this because it starts with a h2 header:I like vertebrates. = VertebrateNeither is this because it has two h1 headers:== Vertebrate I like vertebrates.= Vertebrate I like vertebrates. = Non-vertebrate I don't like non vertebrates. - prevent infinite include loop recursion. E.g. this would lead to an infinite loop at render time:index.bigb
= My homepage \Include[vertebrate]vertebrate.bigb= Vertebrate \Include[mammal]mammal.bigb= Mammal \Include[vertebrate]Now you just get a nice error message instead. - every file must be recursively included from the toplevel index file. E.g.index.bigb
= My homepage \Include[vertebrate]vertebrate.bigb= Vertebratemammal.bigb= Mammalwould give an error becausemammal.bigbis not included from anywhere. To fix it you would likely want:vertebrate.bigb= Vertebrate \Include[mammal] - files cannot be included twice. Previously the following was allowed:index.bigb
= My homepage \Include[vertebrate] \Include[mammal]vertebrate.bigb= Vertebrate \Include[mammal]mammal.bigb= MammalBut now it gives an error becausemammal.bigbis included from bothindex.bigbandvertebrate.bigb.To fix it you would likely instead want to include it only from the most specific locationvertebrate.bigband remove it fromindex.bigb:index.bigb= My homepage \Include[vertebrate]
It is a common issue with most plaintext note taking systems that they don't force you to make a consistent tree.
However, for publishing, having one tree is essential, otherwise it can be very hard for users to navigate your content.
Furthermore, this makes things much simpler to implement and understand for OurBigBook Web and a future WYSIWYG local editor.
Some other pedantry:
- rename
README.bigbtoindex.bigbfor the the toplevel index file. Much cleaner, and we already have a conflict on the baseneme index with index.html, so why create another conflict with README - rename the
_outdirectory fromoutto_out, which is a reserved ID. Otherwise it was impossible to have a directory calledoutwith ourbigbook files for directory-basedscope.
While OurBigBook Web topic mind melding remains the most innovative feature of the project, local plaintext is a fundamental guarantee that you will never lose your content, and we intend to keep it awesome.
Announcements:
At github.com/ourbigbook/ourbigbook/commit/075872a0a5ca7faf171d45834bc2b47995a15634 and nearby previous commits we've optimized the database queries made on article pages, mostly by adding some key missing indices and cache columns.
As a result, ourbigbook.com/cirosantilli now starts downloading the first byte 2x as fast as before, going down from about 1200 ms to around 600 ms, at a time region which makes a huge difference for user experience.
We will also start keeping better performance logs at: Section "OurBigBook Web performance log" to make sure we don't regress as easily.
Announcements:
We've greatly improved the Visual Studio Code extension adding support for the most important VS Code language features: Ctrl + T header search, Ctrl + click jump to header, header outline and link autocomplete
Thanks to Juhani Junkala for the awesome CC0 chiptune game soundtrack! opengameart.org/content/5-chiptunes-action
OurBigBook Visual Studio Code extension
. Source. Announcements:
The article body now shows by default on all article lists. So do comment lists.
The major application of this is to quickly browser through a users's top or latest posts, e.g. ourbigbook.com/go/user/cirosantilli/articles?sort=score
Previously, the body would only show on:
- topic listings
- discussion comment lists
Now it shows everywhere else as well, except that in other views, only a fixed height preview is shown to allow quickly going through large articles without too much scrolling.
A "view more" button can uncover the hidden content if the user wishes to usee it.
A "Show body" control was also added to toggle body vs the previously existing table mode.
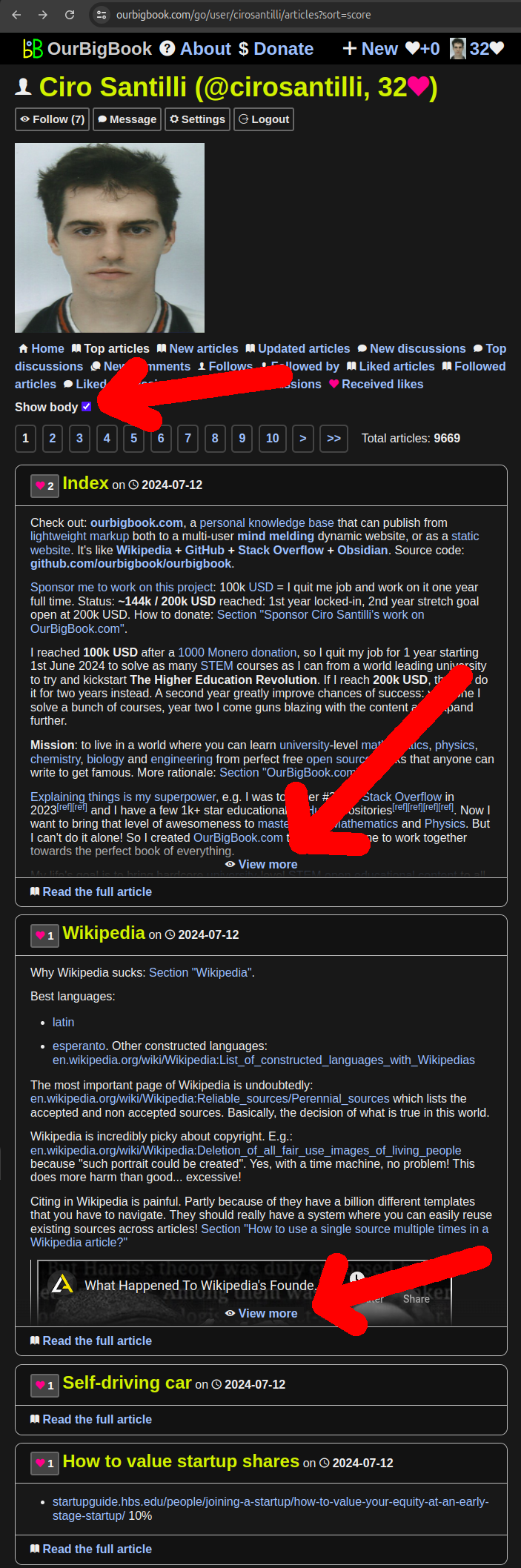
View more and show body demo
. Announcements:
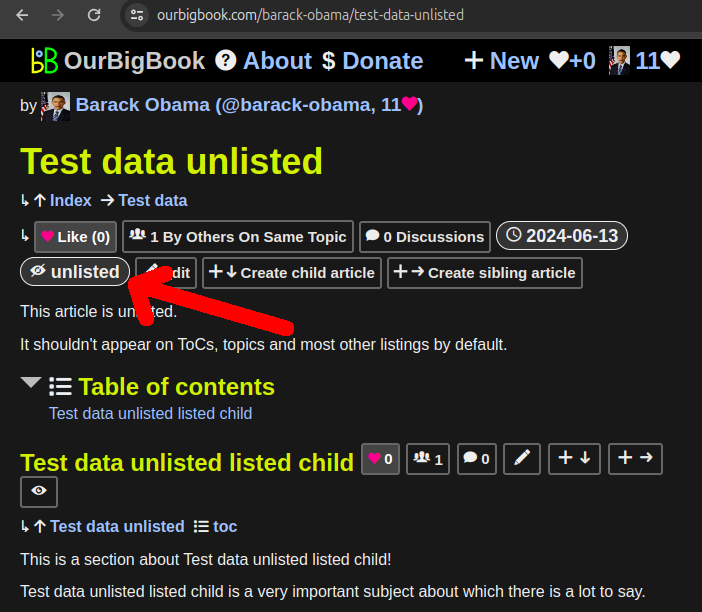
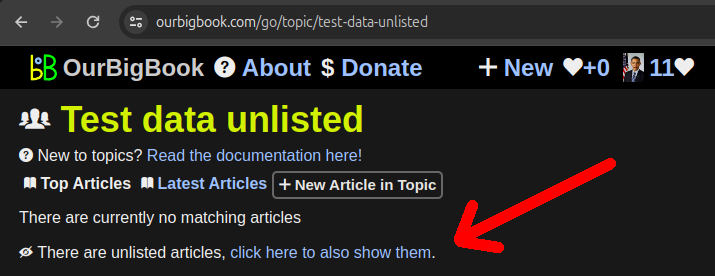
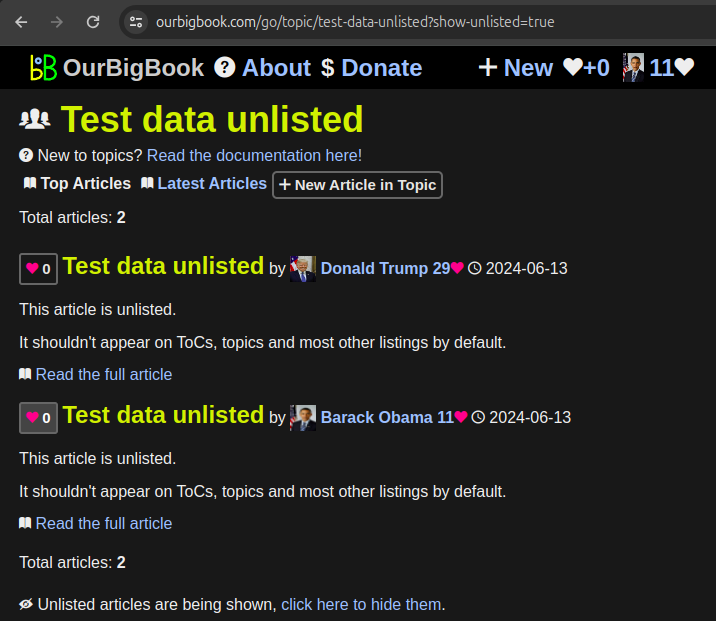
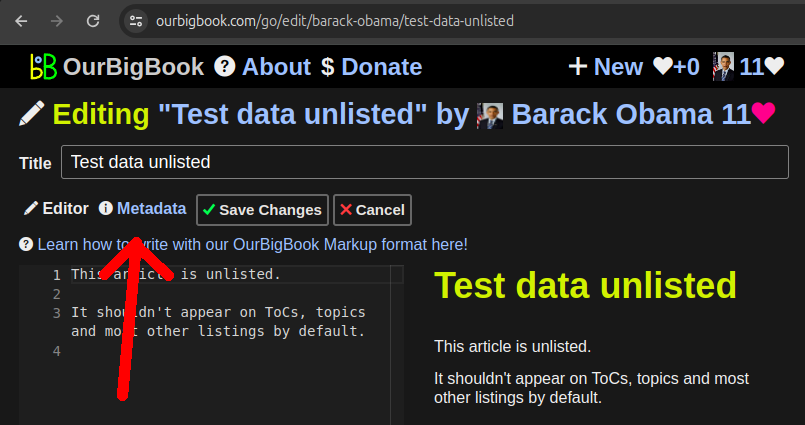
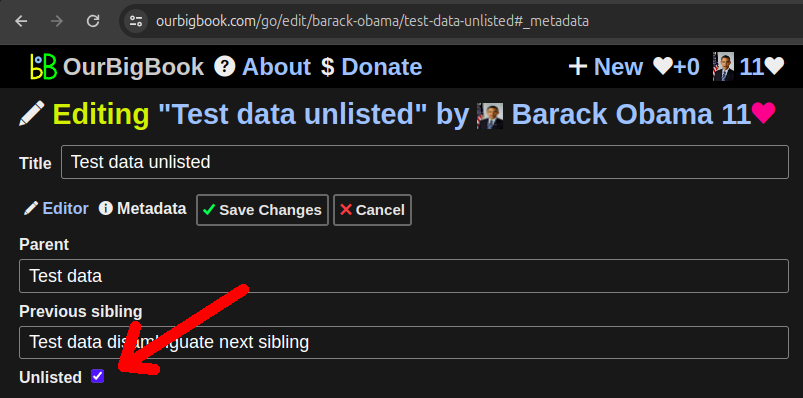
It is now possible to mark articles as unlisted on OurBigBook Web: Section "OurBigBook Web unlisted articles".
The most important effect of this is that unlisted articles don't show on the table of contents of its ancestors. They also don't show on many article listing by default, e.g. on the list of user's latest articles.
The main use case we have for this feature right now is to stop polluting the table of contents with articles a user does not wish to show, and especially when doing local to Web upload, where Web articles are marked as unlisted by default if they are deleted locally.
We offer unlisted as an alternative to deletion for now because of the general philosophy what "permalinks should never break". This is currently not true as we don't have article history and therefore no permalinks. However, once history is implemented, we want to make it so links to specific versions will never ever break by forbidding article and history deletion entirely. Marking articles as unlisted will then allows to prevent deletion, while still keeping table of contents tidy.
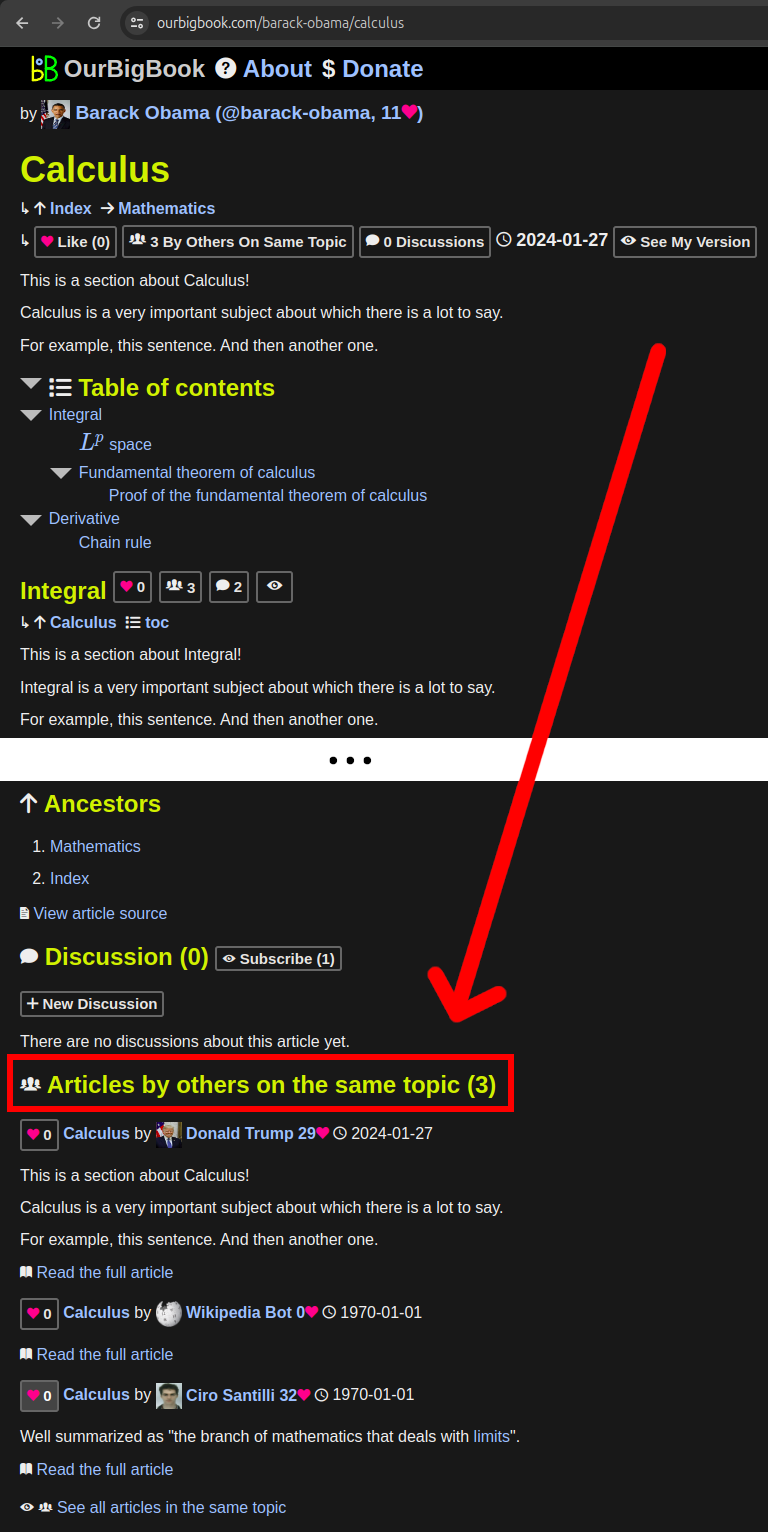
In order to give more immediate topic value to readers, and to better highlight the topics feature, we now show a few articles on the same topic at the bottom of every article page, essentially acting as a preview of the corresponding topic page.
For example, if you visit the "Calculus" article by user Barack Obama: ourbigbook.com/barack-obama/calculus then at the bottom of the page you can see a section "Articles by others on the same topic (3)" which displays up to the 5 most highly upvoted articles in the same topic written by other users, much like the topic page for the "Calculus" topic: ourbigbook.com/go/topic/calculus.
By comparison, the topic page shows more articles by default (20), supports pagination, and allows for other forms of sorting such as viewing the latest articles in a topic. We are initially not adding those options to the article page itself as there is already enough stuff going on there.
Announcements:
Previously, when clicking a link to an element that is present in the current page, the URL fragment would contain the full ID that element.
Now, only the ID relative to URL path shows.
A very common use case for this is when clicking table of content items.
For exmple, from ourbigbook.com/barack-obama/mathematics, clicking the ToC item for "Calculus" would previously lead to ourbigbook.com/barack-obama/mathematics#barack-obama/calculus
After this change it leads just to: ourbigbook.com/barack-obama/mathematics#calculus, without repeating the "
#barack-obama part as it already appears in the URL path /barack-obama/mathematics.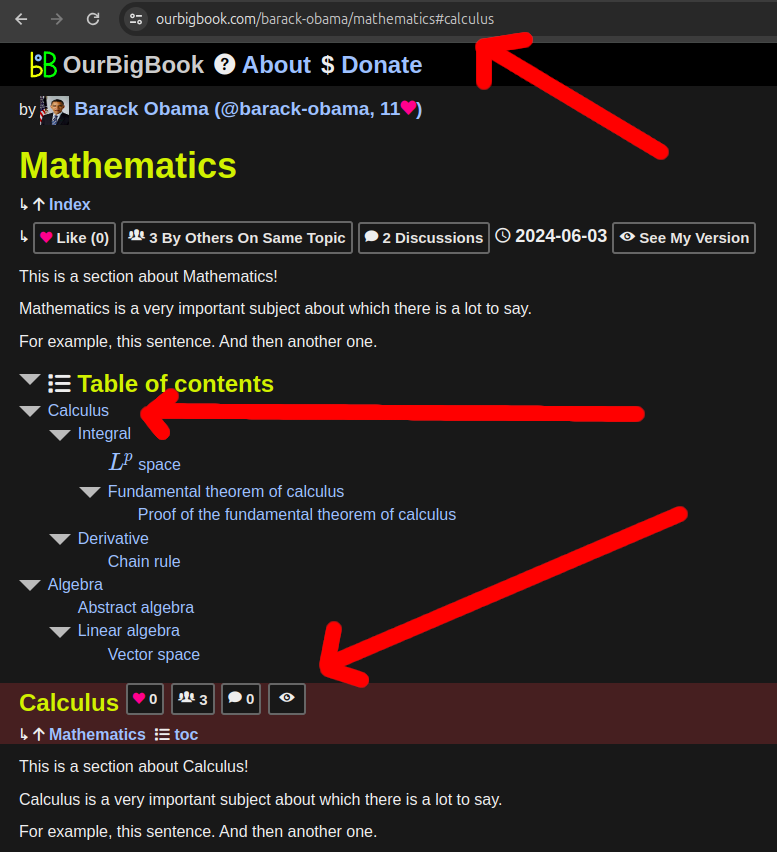
Short URLs were already used on Static website publishes, and weren't implemented on OurBigBook Web yet simply because this is hard. The reason this was much harder to implement on Web is that due to Dynamic article trees we can't know at render-time what the correct fragment will be, as it depends on what shows on the page or not.
And furthermore, articles by different users can appear on the same page due to topics.
The simple but not ideal solution that we were using up to now was to just have full IDs on every HTML element, make every a point to an absolute ID like
/barack-obama/mathematics, and then use JS effect to hack that to #barack-obama/mathematics if the element is in the page.What we did now is to take the Js hacks one step further, and actually replace the "long URLs" with short ones. This was not easy, partly because the browser interfaces are not amazing in that area, partly due to fighting with React. But we manage to get it working mostly well.
Announcements:
Behold:
Before the rule.
More before the rule.
\Hr
After the rule.
More after the rule.which renders as:
Before the rule.More before the rule.After the rule.More after the rule.
We're experimenting with a more traditional and boring "dark" theme than the green on black classic previously used.
Readability is probably slightly better, though it is hard to measure these things. It is quite possible that the change matter much more for some people than others who have different eye sight phenotypes.
Perhaps the most important outcome of this is that it will greatly reduce the endless complaining from the community. Though perhaps that was a feature rather than a bug?
Beyond the theme change, many other changes were made. Many of those improvements feel like undisputable upgrades, e.g.:
- headers are not colored differently from regular text
- table borders are less visible
- navbar and footer are more discrete and readable
The CSS code was also refactored and it is not much easier to make broad color changes such as these in the future, as color constants are not more closely grouped, and fewer constants are now used.
Large parts of this change were pushed forward by sidstuff who contributed a several code snippets and ideas to it.
Intro to the OurBigBook Project
. Source. It is now possible for admins pin an article to the homepage. The initial use case is to help with new user onboarding. Documentation: pinned article.
Previously we would only create an entry in the
_file output directory for headers marked wiht the \H file argument.For example the file file_demo/hello_world.js in this repository has an associated header with the
file argument in our index.bigb := file_demo/hello_world.js
{file}
An explanation of what this text file is about.
Another line.As a result, when doing a split header conversion, it would get both:
- a
_fileoutput directory page at path_file/file_demo/hello_world.jsfile_demo/hello_world.js - a
_rawdirectory page at path_raw/file_demo/hello_world.jsfile_demo/hello_world.js
On the other hand, the test file file_demo/nofile.js has no such associated header in the source code.
Before this change, file_demo/nofile.js would only get an
_raw directory entry under _raw/file_demo/nofile.js and not _file entry. But now it also gets both.The advantages of a
_file entries over _raw entries are as follows:_fileentries can have metadata such as:- OurBigBook content associated to them when they have an associated
_fileheader. For example at file_demo/hello_world.js we can see the rendered text:Of course, in that case, they would also get theAn explanation of what this text file is about.Another line._fileentry even before this update. However, this update does allow for a smooth update path where you can first link to the_fileentry from external websites, and then add comments as needed later on without changing URLs. - Google Analytics and other features via ourbigbook.liquid.html
- OurBigBook content associated to them when they have an associated
_filealways shows on static website hosts like GitHub Pages, since they are just HTML pages. This is unlikerawfiles which may just get downloaded for unknown extensions like.bigbrather than displayed on the browser:_rawfiles are downloaded rather than displayed in browser for certain file extensions on GitHub Pages
This change is especially powerful following Always show large text files on
_file split headers.Because we now have
_file entries for every single file, we have also modified _dir directory directory listing pages to link to _file entries as those are generally more useful than _raw which is what they previously linked to. And you can always reach _reaw_ from the corresponding _file is needed. Example: docs.ourbigbook.com/_dirPreviously, large files with an rather than the file contents both on their split and non-split versions, e.g.:
\H file argument associated to them would show a messageindex.js was not rendered because it is too large (> 2000 bytes)Now, the split version docs.ourbigbook.com/_file/index.js alwayws shows the full text file.
When not in split mode, limiting preview sizes is important otherwise multi-header pages might become far too big. Ideally we would have found a way to reliably use
iframe + loading="lazy" to refer to the file without actually embedding it into the page as we do for images, but we haven't managed to do that so far.This allows us to now see files that were previously not visible anywhere on the rendered HTML without download due to
_raw files are downloaded rather than displayed in browser for certain file extensions on GitHub Pages.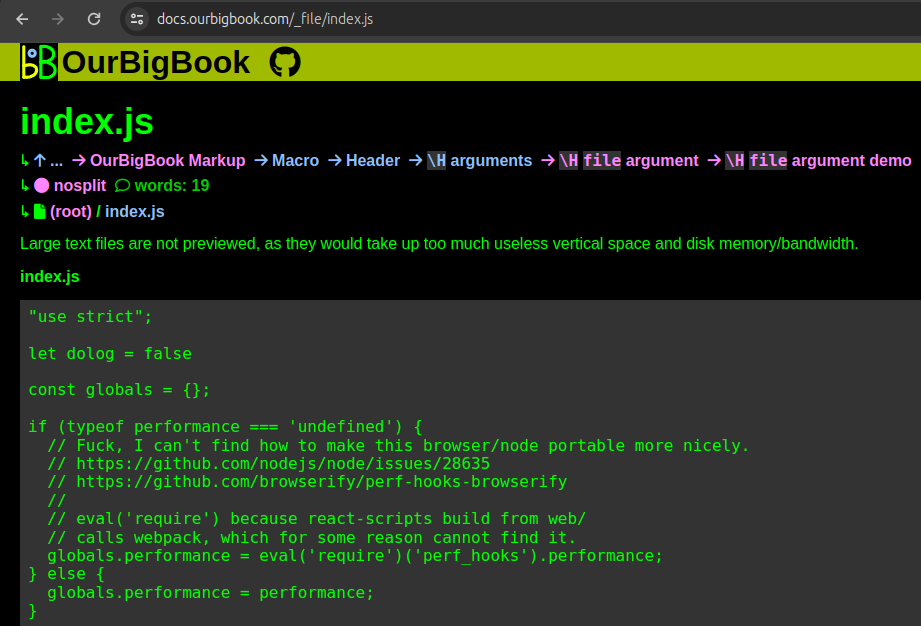
The main focus was the Table of contents rendering, which had a lot of redundant stuff. Headers were the next largest gain.
The main techniques used to reduce size were:
- auto-generate a few elements on-the-fly with JavaScript for on-hover effects, but only if it doesn't affect SEO and readability when JS is turned off
- use a lot more CSS
::afterand::beforeto avoid embedding repetitive icons multiple times on the HTML
After this changes, the rendered size of cirosantilli.com fell from 216 MiB to 156.5 MiB, which is kind of cool!
In previous updates we added shorthand topic links which allow you to write
#mathematics to link to OurBigBook Web topics such as: ourbigbook.com/go/topic/mathematicsThe outcome of that however is that it is also easy and correct to create links to topics that don't yet exist on the OurBigBook Web instance.
To make this nicer, we've unconsciously copied Wikipedia once again, and added a "Create an article for this topic" link
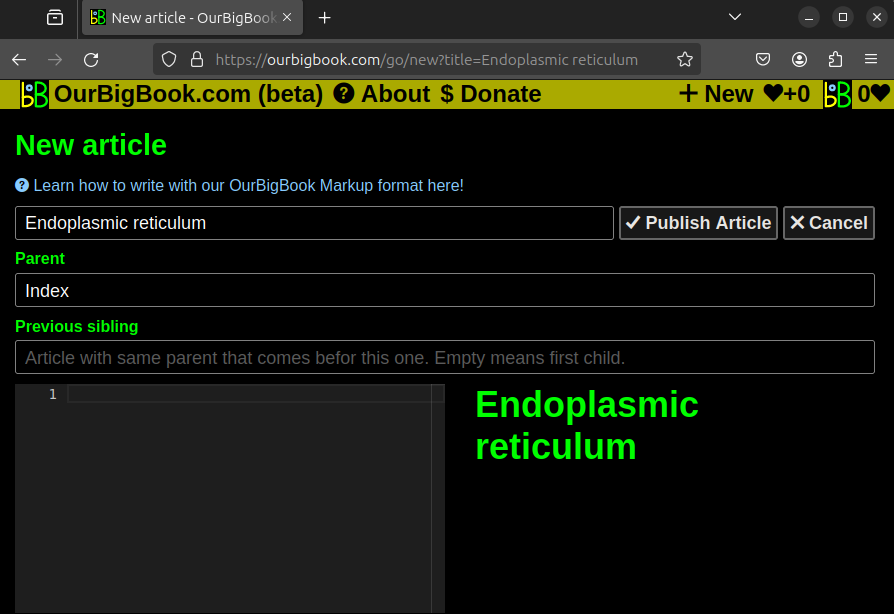
For example, currently OurBigBook.com the topic "Endoplasmatic Reticulum" does not have any articles on it. So if you created a link
<#endoplasmatic reticulum>, it would redirect you to: ourbigbook.com/go/topic/endoplasmic-reticulumPreviously, this would show "Topic does not exist". But now it shows a button that opens the new article editor with pre-filled title "Endoplasmatic reticulum". The title choice is only a heuristic as it can't know the correct capitalization, but it covers most cases corectly by default and can be modified manually as needed.